

Crystal has made a huge step forward to have parallelism as a first class citizen. In short, you can set up the number of worker threads on runtime and each new fiber will be scheduled to run on one of them. Channel and select will work seamlessly. You are allowed to share memory between workers, but you will probably need to take care of some synchronization to keep the state consistent.
This work required a lot of effort, but it definitely got lighter thanks to the refactors, design discussions and attempts to work on parallelism. Either merged or not, all the past work served as a reference to double check thoughts along the way.
In this article, we will try to cover all the new functionality description, design, challenges we faced and next steps. If you want to start using this right away the first section can be enough. The ultimate goal is to be able to use all the CPU power available, but not changing the language too much. Hence, some of the challenges and open work that can be found towards the end of the article.
How to use it, the quick guide
In order to take advantage of these features you need to build your program with preview_mt support. Eventually this will become the default, but for now you need to opt-in.
As you will read in this document, data can be shared across workers but it’s up to the user to avoid data races. Some std-lib parts still need to be reworked to avoid unsound behaviours.
- Build the program with
-Dpreview_mt.crystal build -Dpreview_mt main.cr - Run
./main. (Optionally specify the amount of workers thread as inCRYSTAL_WORKERS=4, by default is4)
The first top-level change in the API is that, when spawning new fibers, you can specify if you want the new one to run in the same worker thread.
spawn same_thread: true do
# ...
end
This is particularly useful if you need to ensure certain thread local state or that the caller is the same thread.
Early Benchmarks
The benchmarks shown in this section were generated from bcardiff/crystal-benchmarks using manastech/benchy in a c5.2xlarge EC2 instance.
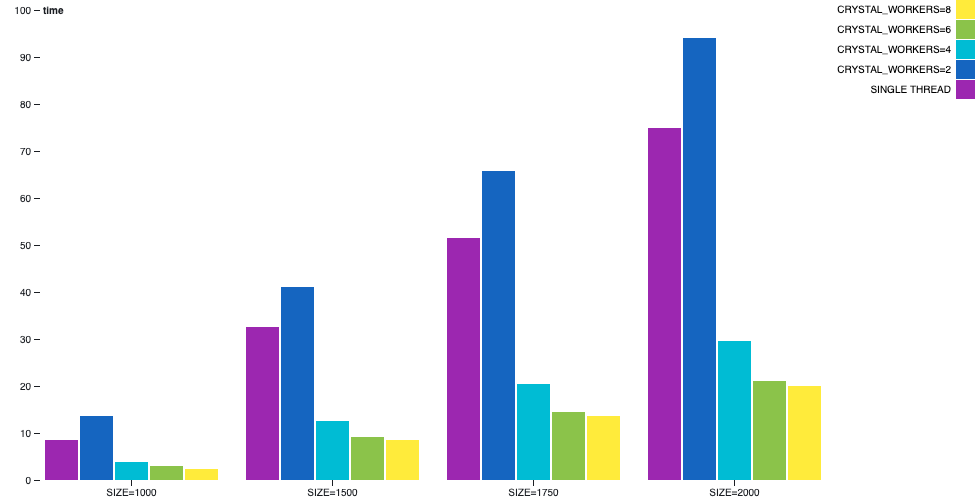
Matrix Multiplication
Multiplying matrices is a process that can be parallelized and scales nicely. It also happens to have no I/O so it’s a good example to analyze a CPU-bounded scenario.
In this example, when compiled with multi-thread, one worker thread will delegate and wait for completion of the result for each of the coordinates, while the other worker threads will be picking requests of computation and processing them.
When we compare single-thread with the 1 worker thread doing the actual computation, we can see some increase in the user time. It is slower due to the heavier bookkeeping and synchronization in multi-thread with respect to single-thread. But as soon as workers are added the user will experience a great deal of improvement in performance. Expect all the threads to be running at top speed in this scenario.
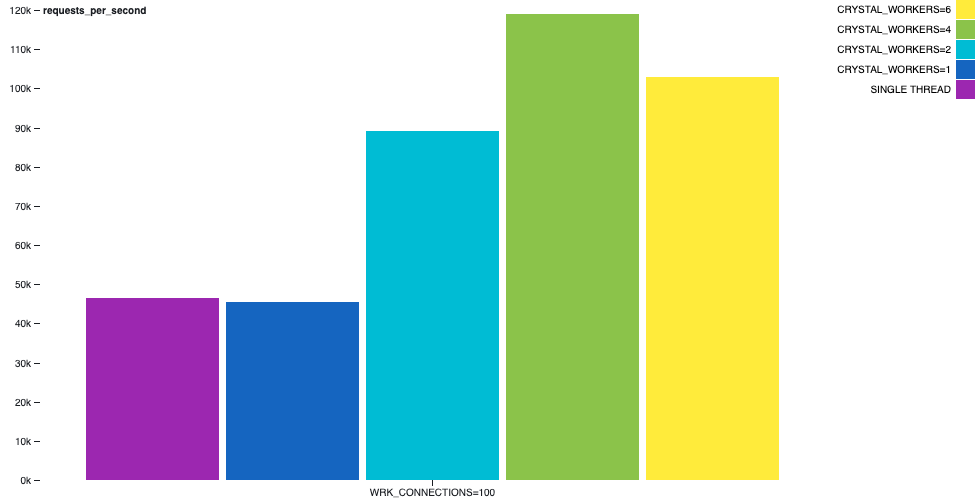
Hello World HTTP Server
A synthetic benchmark that usually appears is an http server that replies hello world to a GET / request. While attending each request and building the short response, there will usually be no need for a context-switch, due to I/O operations while building the response.
For example, in the following chart we can depict how the hello-world-http-server sample behaves. The wrk tool performing on the same machine, with 2 threads and 100 connections during 30 seconds. There is an interesting increase in the throughput.
Channel Primes Generation
In the channel-primes example, the primes are generated by chaining multiple channels in a sort of sequence. The n-th prime will go through n channels before printed. This can be seen as a pathological scenario since the algorithm can’t be balanced in an obvious way and there is a lot of communication happening.
In this example we can see that multi-thread is not a silver bullet. The single-thread still outperforms the multi-thread.
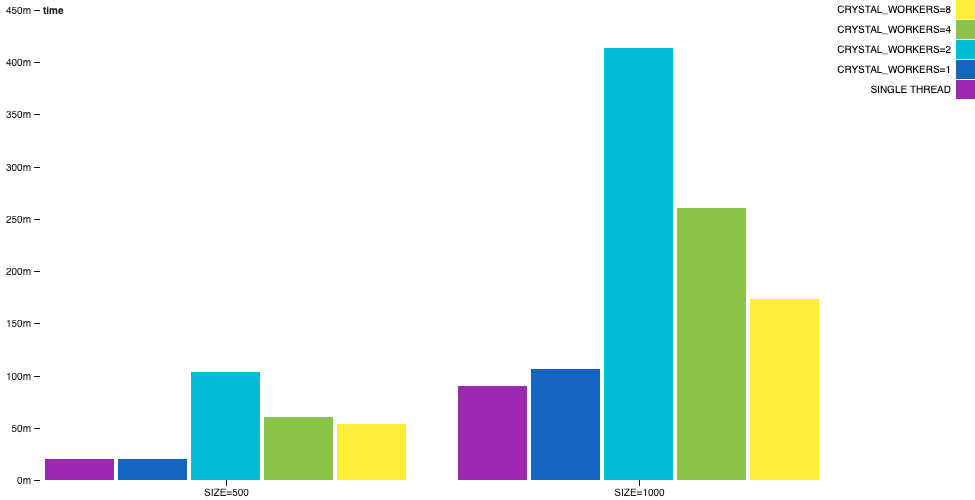
Although, depending on the number of workers the wall time difference is less noticable, the cpu time difference will be huge.
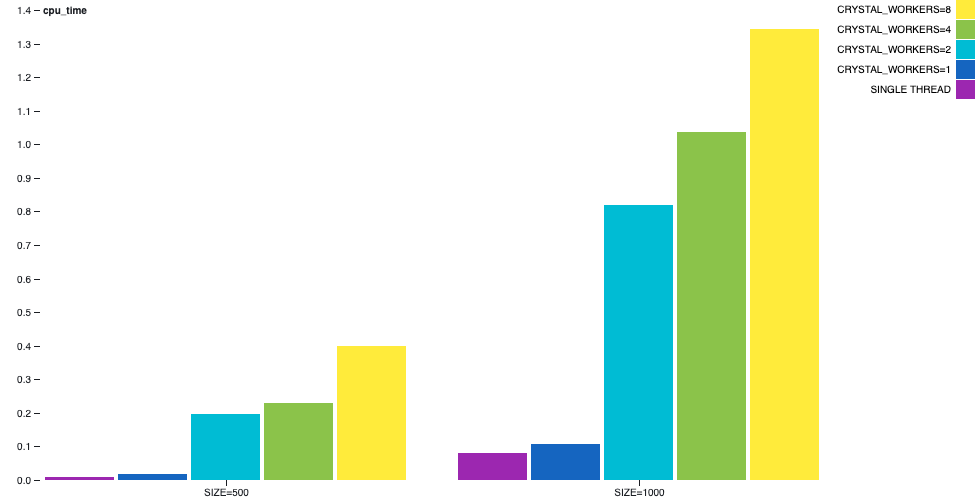
Detailed description
We wanted to bring support for parallelism without changing the nature of the language. The programmer should be able to think in units of fibers running, accessing data and, in most cases, not care which thread the code is running in. This implies shared data among threads and fibers. And keeping the threads hidden from the user as much as possible.
Along the way we needed to deal with some changes in the internal implementation and design of some core aspects of the runtime. We also needed to fix some issues in the compiler itself: some were extracted and submitted independently. And last but not least, some issues regarding the sound and safety of the language itself are currently affected by enabling multi-thread.
In single-thread mode there is one worker thread with one event loop. The event loop is responsible of resuming fibers that are waiting for I/O to complete. In multi-thread mode each worker thread has its own event loop and they work basically as multiple instances of the previous mechanism, but with some additional features.
The memory between each worker thread can be shared and is mutable. This is and will be the source of many headaches. You will need to synchronize access to them via locks or use some proper data-structures that can handle concurrent access.
The channels are able to send and receive messages through different worker threads without changes in the API and should be used as the main method of communication and synchronization between fibers.
The select statement needed some extra care on its own. A select injects many receivers and senders on different channels. As soon as one of those fulfills the select, the rest of the receivers and senders need to be ignored. To this end, when a fiber is enqueued as sender or receiver in a select operation, a SelectContext is created to track the state of the whole select. On Channel#dequeue_receiver and Channel#dequeue_sender is the logic to skip them if the select was already completed.
As soon as the program starts, the initialization of workers threads based on the value of the environment variable CRYSTAL_WORKERS is done. Each worker thread has its own Scheduler with the runnables queue.
Even on multi-thread mode there is still a short time before workers are initialized when the program will work with only one worker. This happens while initializing some constants and class variables.
Through the Scheduler there are a couple of conditions to protect the state in multi-thread mode. Although the queues are independent, workers need to communicate to one another to dispatch new fibers. If the target worker is not sleeping, the new fiber can be enqueued directly (note that the queue is accessed from the current worker and hence needs to be synchronized). If the target worker is sleeping, a pipe is used to send the new fiber to execute, waking the worker through the event loop. A pipe is created for each worker thread in its scheduler. This is handled in Scheduler#run_loop, Scheduler#send_fiber, Scheduler#enqueue.
Which worker thread will execute a fiber is now decided in a round-robin fashion. This policy might change in the future with some load metric per worker. But we chose the simplest logic we could think of, and it will serve as a baseline for future improvements if needed.
To keep things as simple as possible, regarding the scheduling, once a fiber starts running in a worker thread it will never migrate to another. It can be suspended and resumed, of course. But we explicitly chose to start without fiber stealing.
API Changes
Compiling a multi-thread program
Compiling programs with multi-threading support is available behind the preview_mt flag for now. And check that you are using Crystal 0.31.0 (not yet released) or a local build of master.
$ crystal --version
Crystal 0.31.0
$ crystal build -Dpreview_mt main.cr -o main
Setup the number of worker threads at runtime
The number of worker threads can be customized via CRYSTAL_WORKERS env var. Its default is 4.
$ ./main # will use 4 workers
$ CRYSTAL_WORKERS=4 ./main
$ CRYSTAL_WORKERS=8 ./main
spawn
By default new fibers created with spawn are free to run in any of the worker threads. If you need for the same fiber to execute in current worker thread you can use spawn(same_thread: true) { ... }. This is useful for some C libraries where thread local storage is used.
Mutex
Mutex is still the way to request a lock that works across fibers. There is no actual API changes but is worth noticing that the behavior still holds in multi-thread mode. Some of you might know about the existence of the internal Thread::Mutex that is a wrapper for pthread. Direct use of Thread::Mutex is discouraged, unless you really know what you’re doing and why you’re doing it. Use the top-level Mutex.
Channel
The behaviour of closed channels was revisited. From now on, either in single-thread or multi-thread programs, you will be able to perform a receive action on a closed channel until the already sent messages are consumed. This makes sense because otherwise a sync of the queue and the channel state would be needed. For sure, once the channel is closed, no new messages can be sent through it.
Channel(T) now represents both unbuffered and buffered channels. When initializing them, use Channel(T).new or Channel(T).new(capacity), respectively.
Fork
Mixing fork and multi-thread programs is problematic. There are a couple of references describing issues on that scenario:
- Fork and existing threads?
- Why threads can’t fork
- Threads and fork(): think twice before mixing them
The fork method will not be available in multi-thread and will probably go away as a public API. The std-lib still needs fork to start subprocesses, but this scenario is safe because an exec is performed after the fork.
Another scenario that might need fork is to daemonize a process, but that story needs to evolve a bit still.
Locks
There is an internal implementation of a Spin-Lock in Crystal::SpinLock that, when compiled in single-thread, behaves as a Null-Lock. And there is also an internal implementation of a RW-Lock in Crystal::RWLock.
These locks are used in the runtime and not expected to be used as a public API. But it’s good to know about their existence.
Challenges
We went through a couple of iterations before arriving to the current design for multi-thread support. Some of them were discarded due to performance reasons but were similar in essence and API to the current one. Other ideas inspired us to have some level of isolation between processes. Having some clear boundaries makes it simpler to reduce locking and synchronizations. Some of those designs, partially influenced by Rust, would have led to shareable and non-shareable types between processes and new types of closures to mimic whether they could or could not be sent to another process. There were other draft ideas, but we eventually settled on something that will be more aligned with the current nature of a program of running fibers accessing shared data, since we arrived at an implementation we found performant enough. Besides the implementation details to keep the runtime working there are a couple of stories around language semantics that still need to evolve, but as long as you synchronize the shared state you should be safe.
The lifecycle of a channel changed a bit. In short, when a fiber is waiting for a channel, the fiber is no longer runnable. But now, the awaited channel operation has already a designated memory slot where the message should be received. When a message is to be sent through that channel, it will be stored in the designated memory slot (shared memory FTW). Finally, the fiber that was paused will be rescheduled as runnable and the very first operation will be to read and return the message. This can be seen in the Channel#receive_impl method. If the awaiting fiber was in a thread that was sleeping (no runnable fibers available), the same pipe used to deliver new fibers is used to enqueue the fiber in the sleeping thread, waking it up.
While implementing the changes for channel and select we needed to deal with some corner cases, like a select performing send and receive over the same channel. And we also found ourselves rethinking the invariants of the representation of the channel. It meant a lot to us when we arrived at a design that held similar constraints as those of Go’s channels.
(..) At least one of c.sendq and c.recvq is empty, except for the case of an unbuffered channel with a single goroutine blocked on it for both sending and receiving using a select statement (…) source
The channel mechanism described above works because of how the event loop is designed. Each worker thread has its own event loop in Scheduler#run_loop that will pop fibers from the runnable queue or, if empty, will wait until a fiber is sent through the pipe of that worker thread. This mechanism is not only for channels, but for I/O in general. When an I/O operation is to be waited for, the current fiber will be on hold in the IO internal queue readers or writers queue until the event is completed in IO::Evented#evented_close. Meanwhile, the worker thread can keep running other fibers or become idle. The fiber that was performing I/O is restored by Scheduler.enqueue, which will handle the logic to communicate to a busy or idle thread.
For the integration with libevent we also needed to initialize one Crystal::Event::Base per worker thread. We want the IO to be shareable between workers directly and each of them needs a reference to a Crystal::Event that wraps the LibEvent2::Event. The Crystal::Events are bound to a single Crystal::Event::Base. The solution was that each IO (via IO::Evented) has the event and waiting fibers for it in a hash indexed per thread. When an event is completed on a thread it will be able to notify the waiting fiber of that thread only.
The @[ThreadLocal] annotation is not widely used and it has some known issues in OpenBSD and others platforms. An internal Crystal::ThreadLocalValue(T) class was needed to mimic that behavior and is used in the underlying implementation of IO.
Constants and class variables are lazily initialized in some scenarios. We would like that to change eventually, but for now a lock is needed during the initialization. Where to put that lock remains a challenge. Because it can’t be in a constant, right? Both __crystal_once_init and __crystal_once, internal functions well-known by the compiler, are introduced and used in the lazy initialization functions of constants and class variables.
We mentioned that the starting scheduling algorithm is a round-robin without fiber stealing. We attempted to have a metric of the load of each worker, but since workers can communicate within each other to delegate new fibers, computing the load would imply more state that needs to be synced. On top of that, in the current implementation there are references to fibers in the pipe used for communication, so the @runnables queue sizes are not an accurate metric.
The GC had multi-thread support in the past, but the performance was not good enough. We finally implemented a RW-Lock between context switches (the readers) and the GC collection (the writer). The implementation of the RW-Lock is inspired in Concurrency Kit and does not use a Mutex.
Unsurprisingly, but worth noticing, a compiler built with multi-thread support does not yet take advantage of the cores. Up until now, the compiler used fork when building programs in debug mode. So the --threads compiler option is ignored on multi-thread due to the issues described before. This is a use case of fork that will not be supported in the future and will need to be rewritten with other constructs.
We will probably aim to keep the single-thread mode available: multi-thread is not always better. This could impact in the realm of shards. It is still unclear whether a shard will explicitly be constrained to work on either mode, but not the other one and, if so, how to state it.
Some of the memory representation and the low level instructions emitted by the compiler to manipulate them do not play nicely with multi-thread mode. At the very least, we need to prevent segfaults to keep the language sound. Again, as long as access to shared data is synchronized, you will be fine, but that means the programmer is responsible and the language is not safe enough. In the following sections we depict some scenarios and the current state to solve them.
Language type-safety
When a data structure is accessed concurrently from different threads, if there is no synchronization, the instructions can get interleaved and lead to unexpected results. This problem is not new and many languages suffer it. When dealing with data structures like Array one can think of some synchronization around the public API in a worst case scenario. But sometimes the inconsistent state can manifest in more subtle ways.
If the language allows value-types larger than the amount of memory than can be atomically written, then you might notice some oddities. Let’s assume we have a shared Tuple(Int32, Bool) in which a thread constantly sets the value {0, false}, a second thread sets the value {1, true}, and a third thread will read the value. Due to interleaved instructions, the last thread will every now and then find the values {1, false} and {0, true}. Nothing unsafe happens here, they are possible values of Tuple(Int32, Bool), but it’s odd that a value that was never written can be read. Many languages that have value types of arbitrary size usually exhibit this issue.
In Crystal, unions between value-types and reference-types are represented as a tuple of a type id and the value itself. A union of Int32 | AClass is guaranteed to not have a nil value. But due to interleaving, the representation of a nil can appear, and a null pointer exception (a segfault in this case) will happen.
Regarding Array, something similar can happen. An Array of a reference type (without nil as value) can lead to a segfault, because one thread might remove an item while another is dereferencing the last one. Removing items writes a zero in the memory, so the GC can claim the memory, but the zero address is not a value that can be dereferenced.
There are a couple of ideas to perform the codegen of unions in a different way. And one of them is already working, but at the cost of increasing both the memory footprint and the binary size of the program. We want to iterate on other alternatives and compare them before choosing one. For now you will need to be aware that shared unions that can appear in class variables, instance variables, constants or closured variables are not safe (but will be).
To deal with the Array unsafe behavior, there needs to be a discussion regarding the different approaches and guarantees one might want in shared mutable data structures. The strongest guarantee would be similar to serializing its access (think of a Mutex around every method); a weaker guarantee would be that access is not serialized but will always lead to consistent state (think that every call will produce a consistent final state, but there is no guarantee which one will be the one used); and finally, the void guarantee that is allowing interleaved manipulation of the state.
After the guarantee level is chosen we need to find an algorithm for it. So far, we have worked around an implementation with the weaker one. But it requires some integration with the GC. That integration is currently a bottleneck and we are still iterating. For now you will need to be aware that shared arrays are not safe unless manually synchronized.
The challenges found in Array appear in every manipulation of pointers. Pointers are unsafe and, while working on the code of Array, we definitely wished to have safe/unsafe sections in the language to guide the review process. There are other structures like Deque that suffer from the same issues.
Next Steps
Although there is some pending work to be done before we can claim that multi-thread mode is a first class citizen of the language, having this update in the runtime is definitely a huge step forward. We want to collect feedback and keep iterating so that, in the next couple of releases, we can remove the preview from preview_mt.
We have been able to do all of this thanks to the continued support of 84codes, and every other sponsor. It is extremely important for us to sustain the support through donations, so that we can maintain this development pace. OpenCollective and Bountysource are two available channels for that. Reach out to crystal@manas.tech if you’d like to become a direct sponsor or find other ways to support Crystal. We thank you in advance!
Crystal has made a huge step forward to have parallelism as a first class citizen. In short, you can set up the number of worker threads on runtime and each new fiber will be scheduled to run on one of them. Channel and select will work seamlessly. You are allowed to share memory between workers, but you will probably need to take care of some synchronization to keep the state consistent.
This work required a lot of effort, but it definitely got lighter thanks to the refactors, design discussions and attempts to work on parallelism. Either merged or not, all the past work served as a reference to double check thoughts along the way.
In this article, we will try to cover all the new functionality description, design, challenges we faced and next steps. If you want to start using this right away the first section can be enough. The ultimate goal is to be able to use all the CPU power available, but not changing the language too much. Hence, some of the challenges and open work that can be found towards the end of the article.
How to use it, the quick guide
In order to take advantage of these features you need to build your program with
preview_mtsupport. Eventually this will become the default, but for now you need to opt-in.As you will read in this document, data can be shared across workers but it’s up to the user to avoid data races. Some std-lib parts still need to be reworked to avoid unsound behaviours.
-Dpreview_mt.crystal build -Dpreview_mt main.cr./main. (Optionally specify the amount of workers thread as inCRYSTAL_WORKERS=4, by default is4)The first top-level change in the API is that, when spawning new fibers, you can specify if you want the new one to run in the same worker thread.
This is particularly useful if you need to ensure certain thread local state or that the caller is the same thread.
Early Benchmarks
The benchmarks shown in this section were generated from bcardiff/crystal-benchmarks using manastech/benchy in a
c5.2xlargeEC2 instance.Matrix Multiplication
Multiplying matrices is a process that can be parallelized and scales nicely. It also happens to have no I/O so it’s a good example to analyze a CPU-bounded scenario.
In this example, when compiled with multi-thread, one worker thread will delegate and wait for completion of the result for each of the coordinates, while the other worker threads will be picking requests of computation and processing them.
When we compare single-thread with the 1 worker thread doing the actual computation, we can see some increase in the user time. It is slower due to the heavier bookkeeping and synchronization in multi-thread with respect to single-thread. But as soon as workers are added the user will experience a great deal of improvement in performance. Expect all the threads to be running at top speed in this scenario.
Hello World HTTP Server
A synthetic benchmark that usually appears is an http server that replies
hello worldto aGET /request. While attending each request and building the short response, there will usually be no need for a context-switch, due to I/O operations while building the response.For example, in the following chart we can depict how the
hello-world-http-serversample behaves. Thewrktool performing on the same machine, with 2 threads and 100 connections during 30 seconds. There is an interesting increase in the throughput.Channel Primes Generation
In the
channel-primesexample, the primes are generated by chaining multiple channels in a sort of sequence. Then-th prime will go throughnchannels before printed. This can be seen as a pathological scenario since the algorithm can’t be balanced in an obvious way and there is a lot of communication happening.In this example we can see that multi-thread is not a silver bullet. The single-thread still outperforms the multi-thread.
Although, depending on the number of workers the wall time difference is less noticable, the cpu time difference will be huge.
Detailed description
We wanted to bring support for parallelism without changing the nature of the language. The programmer should be able to think in units of fibers running, accessing data and, in most cases, not care which thread the code is running in. This implies shared data among threads and fibers. And keeping the threads hidden from the user as much as possible.
Along the way we needed to deal with some changes in the internal implementation and design of some core aspects of the runtime. We also needed to fix some issues in the compiler itself: some were extracted and submitted independently. And last but not least, some issues regarding the sound and safety of the language itself are currently affected by enabling multi-thread.
In single-thread mode there is one worker thread with one event loop. The event loop is responsible of resuming fibers that are waiting for I/O to complete. In multi-thread mode each worker thread has its own event loop and they work basically as multiple instances of the previous mechanism, but with some additional features.
The memory between each worker thread can be shared and is mutable. This is and will be the source of many headaches. You will need to synchronize access to them via locks or use some proper data-structures that can handle concurrent access.
The channels are able to send and receive messages through different worker threads without changes in the API and should be used as the main method of communication and synchronization between fibers.
The
selectstatement needed some extra care on its own. Aselectinjects many receivers and senders on different channels. As soon as one of those fulfills the select, the rest of the receivers and senders need to be ignored. To this end, when a fiber is enqueued as sender or receiver in aselectoperation, aSelectContextis created to track the state of the wholeselect. OnChannel#dequeue_receiverandChannel#dequeue_senderis the logic to skip them if the select was already completed.As soon as the program starts, the initialization of workers threads based on the value of the environment variable
CRYSTAL_WORKERSis done. Each worker thread has its ownSchedulerwith therunnablesqueue.Even on multi-thread mode there is still a short time before workers are initialized when the program will work with only one worker. This happens while initializing some constants and class variables.
Through the
Schedulerthere are a couple of conditions to protect the state in multi-thread mode. Although the queues are independent, workers need to communicate to one another to dispatch new fibers. If the target worker is not sleeping, the new fiber can be enqueued directly (note that the queue is accessed from the current worker and hence needs to be synchronized). If the target worker is sleeping, a pipe is used to send the new fiber to execute, waking the worker through the event loop. A pipe is created for each worker thread in its scheduler. This is handled inScheduler#run_loop,Scheduler#send_fiber,Scheduler#enqueue.Which worker thread will execute a fiber is now decided in a round-robin fashion. This policy might change in the future with some load metric per worker. But we chose the simplest logic we could think of, and it will serve as a baseline for future improvements if needed.
To keep things as simple as possible, regarding the scheduling, once a fiber starts running in a worker thread it will never migrate to another. It can be suspended and resumed, of course. But we explicitly chose to start without fiber stealing.
API Changes
Compiling a multi-thread program
Compiling programs with multi-threading support is available behind the
preview_mtflag for now. And check that you are using Crystal 0.31.0 (not yet released) or a local build of master.Setup the number of worker threads at runtime
The number of worker threads can be customized via
CRYSTAL_WORKERSenv var. Its default is4.spawn
By default new fibers created with
spawnare free to run in any of the worker threads. If you need for the same fiber to execute in current worker thread you can usespawn(same_thread: true) { ... }. This is useful for some C libraries where thread local storage is used.Mutex
Mutexis still the way to request a lock that works across fibers. There is no actual API changes but is worth noticing that the behavior still holds in multi-thread mode. Some of you might know about the existence of the internalThread::Mutexthat is a wrapper for pthread. Direct use ofThread::Mutexis discouraged, unless you really know what you’re doing and why you’re doing it. Use the top-levelMutex.Channel
The behaviour of closed channels was revisited. From now on, either in single-thread or multi-thread programs, you will be able to perform a receive action on a closed channel until the already sent messages are consumed. This makes sense because otherwise a sync of the queue and the channel state would be needed. For sure, once the channel is closed, no new messages can be sent through it.
Channel(T)now represents both unbuffered and buffered channels. When initializing them, useChannel(T).neworChannel(T).new(capacity), respectively.Fork
Mixing fork and multi-thread programs is problematic. There are a couple of references describing issues on that scenario:
The
forkmethod will not be available in multi-thread and will probably go away as a public API. The std-lib still needs fork to start subprocesses, but this scenario is safe because an exec is performed after the fork.Another scenario that might need fork is to daemonize a process, but that story needs to evolve a bit still.
Locks
There is an internal implementation of a Spin-Lock in
Crystal::SpinLockthat, when compiled in single-thread, behaves as a Null-Lock. And there is also an internal implementation of a RW-Lock inCrystal::RWLock.These locks are used in the runtime and not expected to be used as a public API. But it’s good to know about their existence.
Challenges
We went through a couple of iterations before arriving to the current design for multi-thread support. Some of them were discarded due to performance reasons but were similar in essence and API to the current one. Other ideas inspired us to have some level of isolation between processes. Having some clear boundaries makes it simpler to reduce locking and synchronizations. Some of those designs, partially influenced by Rust, would have led to shareable and non-shareable types between processes and new types of closures to mimic whether they could or could not be sent to another process. There were other draft ideas, but we eventually settled on something that will be more aligned with the current nature of a program of running fibers accessing shared data, since we arrived at an implementation we found performant enough. Besides the implementation details to keep the runtime working there are a couple of stories around language semantics that still need to evolve, but as long as you synchronize the shared state you should be safe.
The lifecycle of a channel changed a bit. In short, when a fiber is waiting for a channel, the fiber is no longer runnable. But now, the awaited channel operation has already a designated memory slot where the message should be received. When a message is to be sent through that channel, it will be stored in the designated memory slot (shared memory FTW). Finally, the fiber that was paused will be rescheduled as runnable and the very first operation will be to read and return the message. This can be seen in the
Channel#receive_implmethod. If the awaiting fiber was in a thread that was sleeping (no runnable fibers available), the same pipe used to deliver new fibers is used to enqueue the fiber in the sleeping thread, waking it up.While implementing the changes for channel and select we needed to deal with some corner cases, like a select performing send and receive over the same channel. And we also found ourselves rethinking the invariants of the representation of the channel. It meant a lot to us when we arrived at a design that held similar constraints as those of Go’s channels.
The channel mechanism described above works because of how the event loop is designed. Each worker thread has its own event loop in
Scheduler#run_loopthat will pop fibers from the runnable queue or, if empty, will wait until a fiber is sent through the pipe of that worker thread. This mechanism is not only for channels, but for I/O in general. When an I/O operation is to be waited for, the current fiber will be on hold in the IO internal queue readers or writers queue until the event is completed inIO::Evented#evented_close. Meanwhile, the worker thread can keep running other fibers or become idle. The fiber that was performing I/O is restored byScheduler.enqueue, which will handle the logic to communicate to a busy or idle thread.For the integration with libevent we also needed to initialize one
Crystal::Event::Baseper worker thread. We want theIOto be shareable between workers directly and each of them needs a reference to aCrystal::Eventthat wraps theLibEvent2::Event. TheCrystal::Events are bound to a singleCrystal::Event::Base. The solution was that eachIO(viaIO::Evented) has the event and waiting fibers for it in a hash indexed per thread. When an event is completed on a thread it will be able to notify the waiting fiber of that thread only.The
@[ThreadLocal]annotation is not widely used and it has some known issues in OpenBSD and others platforms. An internalCrystal::ThreadLocalValue(T)class was needed to mimic that behavior and is used in the underlying implementation ofIO.Constants and class variables are lazily initialized in some scenarios. We would like that to change eventually, but for now a lock is needed during the initialization. Where to put that lock remains a challenge. Because it can’t be in a constant, right? Both
__crystal_once_initand__crystal_once, internal functions well-known by the compiler, are introduced and used in the lazy initialization functions of constants and class variables.We mentioned that the starting scheduling algorithm is a round-robin without fiber stealing. We attempted to have a metric of the load of each worker, but since workers can communicate within each other to delegate new fibers, computing the load would imply more state that needs to be synced. On top of that, in the current implementation there are references to fibers in the pipe used for communication, so the
@runnablesqueue sizes are not an accurate metric.The GC had multi-thread support in the past, but the performance was not good enough. We finally implemented a RW-Lock between context switches (the readers) and the GC collection (the writer). The implementation of the RW-Lock is inspired in Concurrency Kit and does not use a Mutex.
Unsurprisingly, but worth noticing, a compiler built with multi-thread support does not yet take advantage of the cores. Up until now, the compiler used
forkwhen building programs in debug mode. So the--threadscompiler option is ignored on multi-thread due to the issues described before. This is a use case offorkthat will not be supported in the future and will need to be rewritten with other constructs.We will probably aim to keep the single-thread mode available: multi-thread is not always better. This could impact in the realm of shards. It is still unclear whether a shard will explicitly be constrained to work on either mode, but not the other one and, if so, how to state it.
Some of the memory representation and the low level instructions emitted by the compiler to manipulate them do not play nicely with multi-thread mode. At the very least, we need to prevent segfaults to keep the language sound. Again, as long as access to shared data is synchronized, you will be fine, but that means the programmer is responsible and the language is not safe enough. In the following sections we depict some scenarios and the current state to solve them.
Language type-safety
When a data structure is accessed concurrently from different threads, if there is no synchronization, the instructions can get interleaved and lead to unexpected results. This problem is not new and many languages suffer it. When dealing with data structures like Array one can think of some synchronization around the public API in a worst case scenario. But sometimes the inconsistent state can manifest in more subtle ways.
If the language allows value-types larger than the amount of memory than can be atomically written, then you might notice some oddities. Let’s assume we have a shared
Tuple(Int32, Bool)in which a thread constantly sets the value{0, false}, a second thread sets the value{1, true}, and a third thread will read the value. Due to interleaved instructions, the last thread will every now and then find the values{1, false}and{0, true}. Nothing unsafe happens here, they are possible values ofTuple(Int32, Bool), but it’s odd that a value that was never written can be read. Many languages that have value types of arbitrary size usually exhibit this issue.In Crystal, unions between value-types and reference-types are represented as a tuple of a type id and the value itself. A union of
Int32 | AClassis guaranteed to not have anilvalue. But due to interleaving, the representation of anilcan appear, and a null pointer exception (a segfault in this case) will happen.Regarding Array, something similar can happen. An Array of a reference type (without
nilas value) can lead to a segfault, because one thread might remove an item while another is dereferencing the last one. Removing items writes a zero in the memory, so the GC can claim the memory, but the zero address is not a value that can be dereferenced.There are a couple of ideas to perform the codegen of unions in a different way. And one of them is already working, but at the cost of increasing both the memory footprint and the binary size of the program. We want to iterate on other alternatives and compare them before choosing one. For now you will need to be aware that shared unions that can appear in class variables, instance variables, constants or closured variables are not safe (but will be).
To deal with the Array unsafe behavior, there needs to be a discussion regarding the different approaches and guarantees one might want in shared mutable data structures. The strongest guarantee would be similar to serializing its access (think of a Mutex around every method); a weaker guarantee would be that access is not serialized but will always lead to consistent state (think that every call will produce a consistent final state, but there is no guarantee which one will be the one used); and finally, the void guarantee that is allowing interleaved manipulation of the state.
After the guarantee level is chosen we need to find an algorithm for it. So far, we have worked around an implementation with the weaker one. But it requires some integration with the GC. That integration is currently a bottleneck and we are still iterating. For now you will need to be aware that shared arrays are not safe unless manually synchronized.
The challenges found in Array appear in every manipulation of pointers. Pointers are unsafe and, while working on the code of Array, we definitely wished to have safe/unsafe sections in the language to guide the review process. There are other structures like Deque that suffer from the same issues.
Next Steps
Although there is some pending work to be done before we can claim that multi-thread mode is a first class citizen of the language, having this update in the runtime is definitely a huge step forward. We want to collect feedback and keep iterating so that, in the next couple of releases, we can remove the
previewfrompreview_mt.We have been able to do all of this thanks to the continued support of 84codes, and every other sponsor. It is extremely important for us to sustain the support through donations, so that we can maintain this development pace. OpenCollective and Bountysource are two available channels for that. Reach out to crystal@manas.tech if you’d like to become a direct sponsor or find other ways to support Crystal. We thank you in advance!